準備編では、jupyter note book の起動まではできました。v3.1 の時と同じように、Welcome.ipynb を開き、チュートリアルをPlay ボタン(➤)で進めてゆきます。
[もっと鮮明な拡大図]
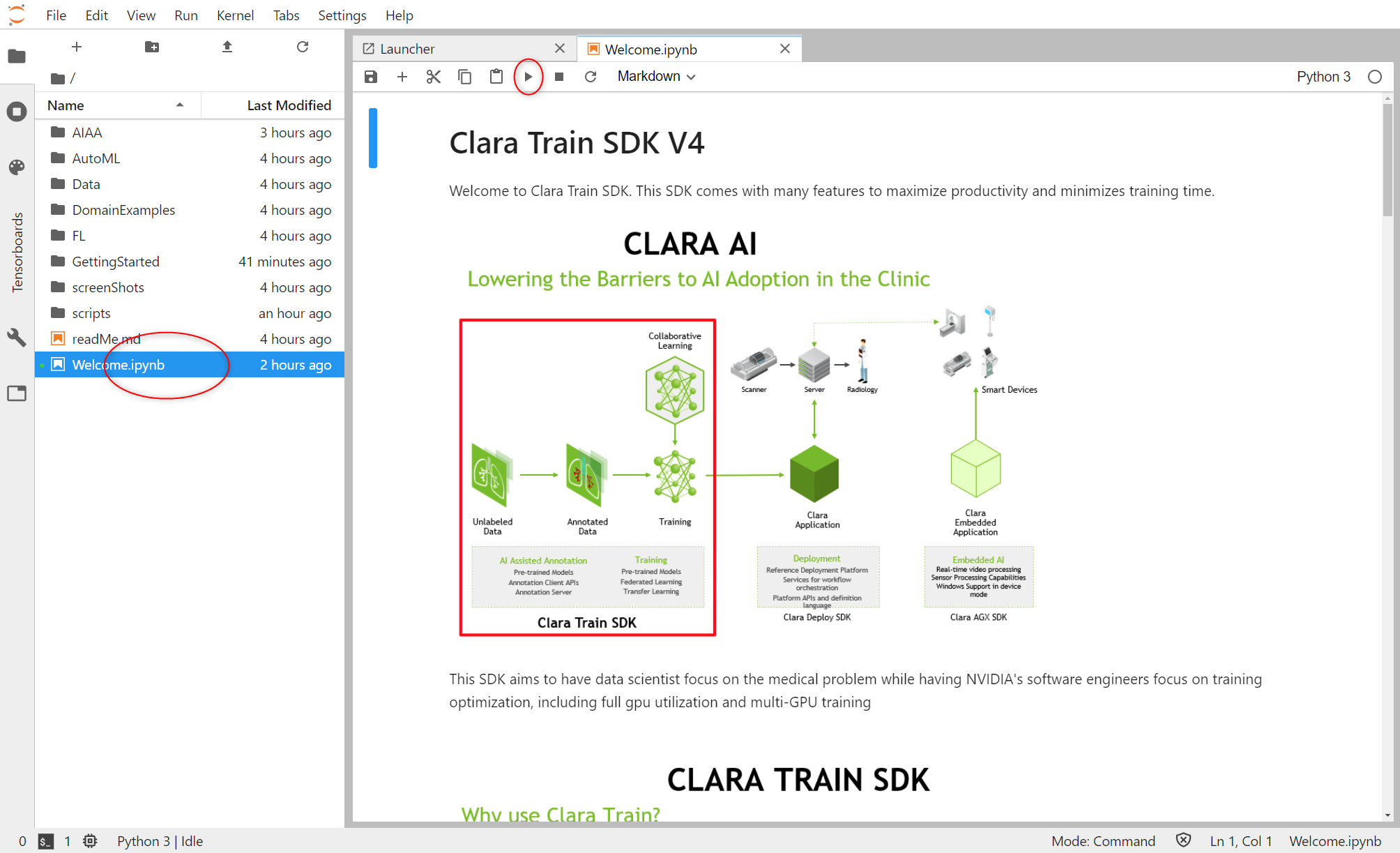
Clara Train SDK が一体なんであるかについては、赤枠にある通り、CT、MNR などで取得した多量の画像データに対して、アノテーション(情報の付与)が行われたデータにするため、すでに学習されたデータに基づき AI による補助を行います。そのデータを収集し、逐次学習する意図により解析制度を上げ次の段である、アプリケーション層につなげるのが役割となります。Clara という名称は現在巨大な系を形成し、データの学習から、末端端末(スマホやロボットのカメラ)などから情報を収集する通観したシステムの総称になっています。すべての系を一つのまとまりで開設することもできませんので、ここでは、 Train SDK についてはじめの一歩を説明しております。
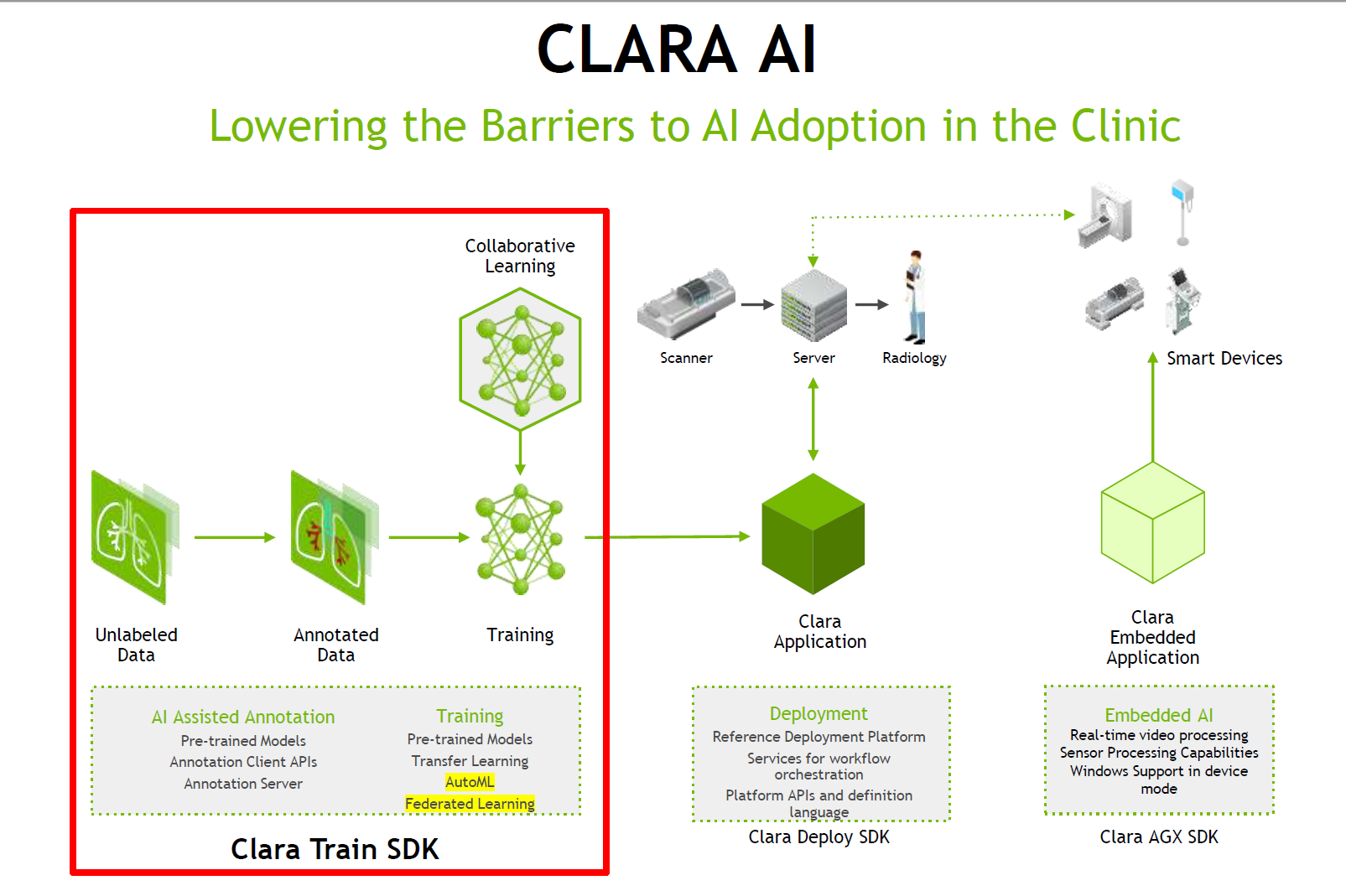
参照される方により見方が異なりますが、ここで解説している視点はデータサイエンティストではなく、エンジニアとしての視点になります。データサイエンティスト向けの解説は、Nvidia さんにお願いしたいと思います。
そうはいっても何から始めていいのかわからないので、まずは、Getting Started から始めましょう。全編英語ですが、GTC2021 Postworkshop で Clara v4.0 の説明とトレーニングがありました。その内容には、
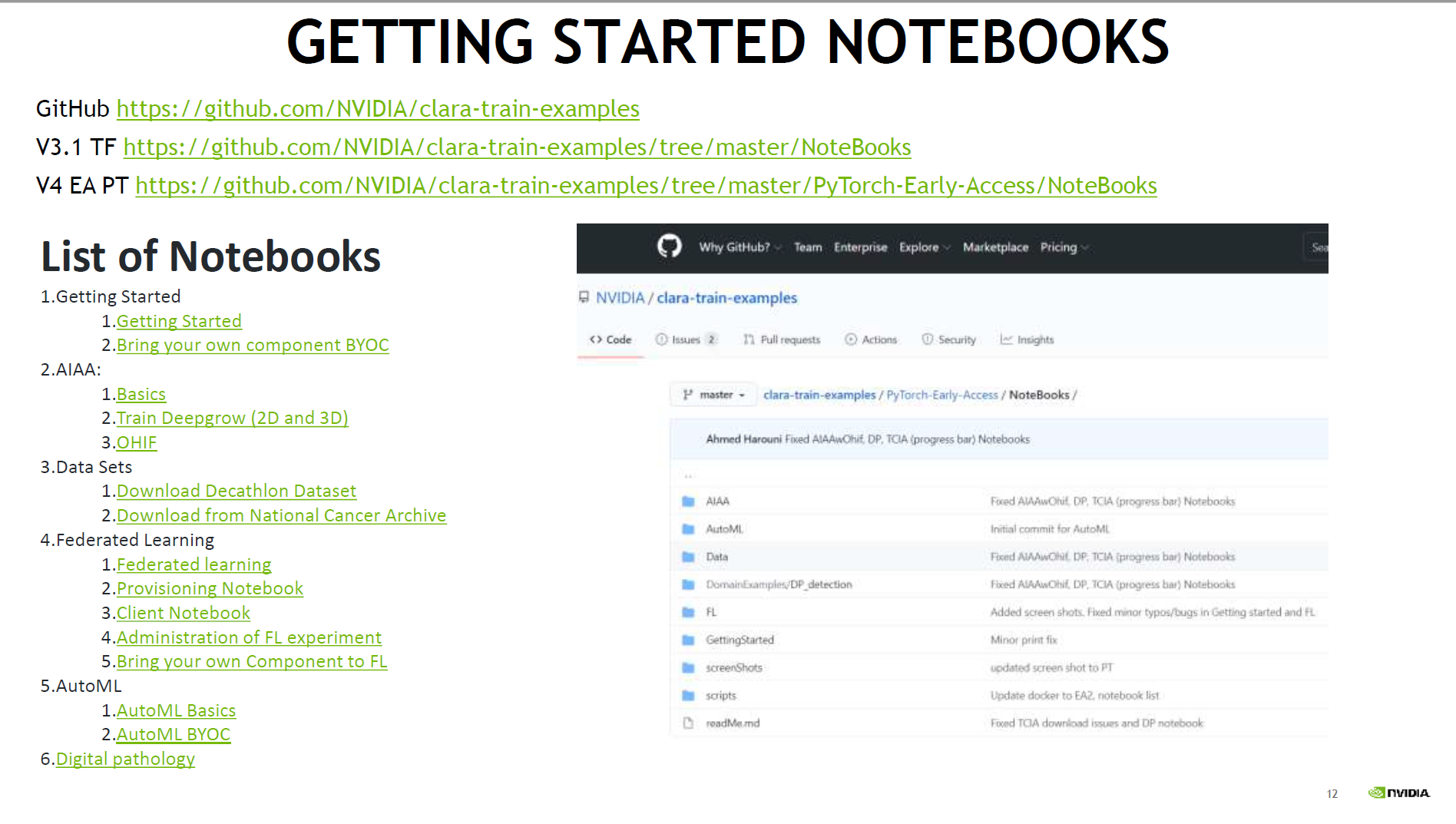
JupyterNoteBookの話があり、ステップごとに理解すればいいよと書かれています。
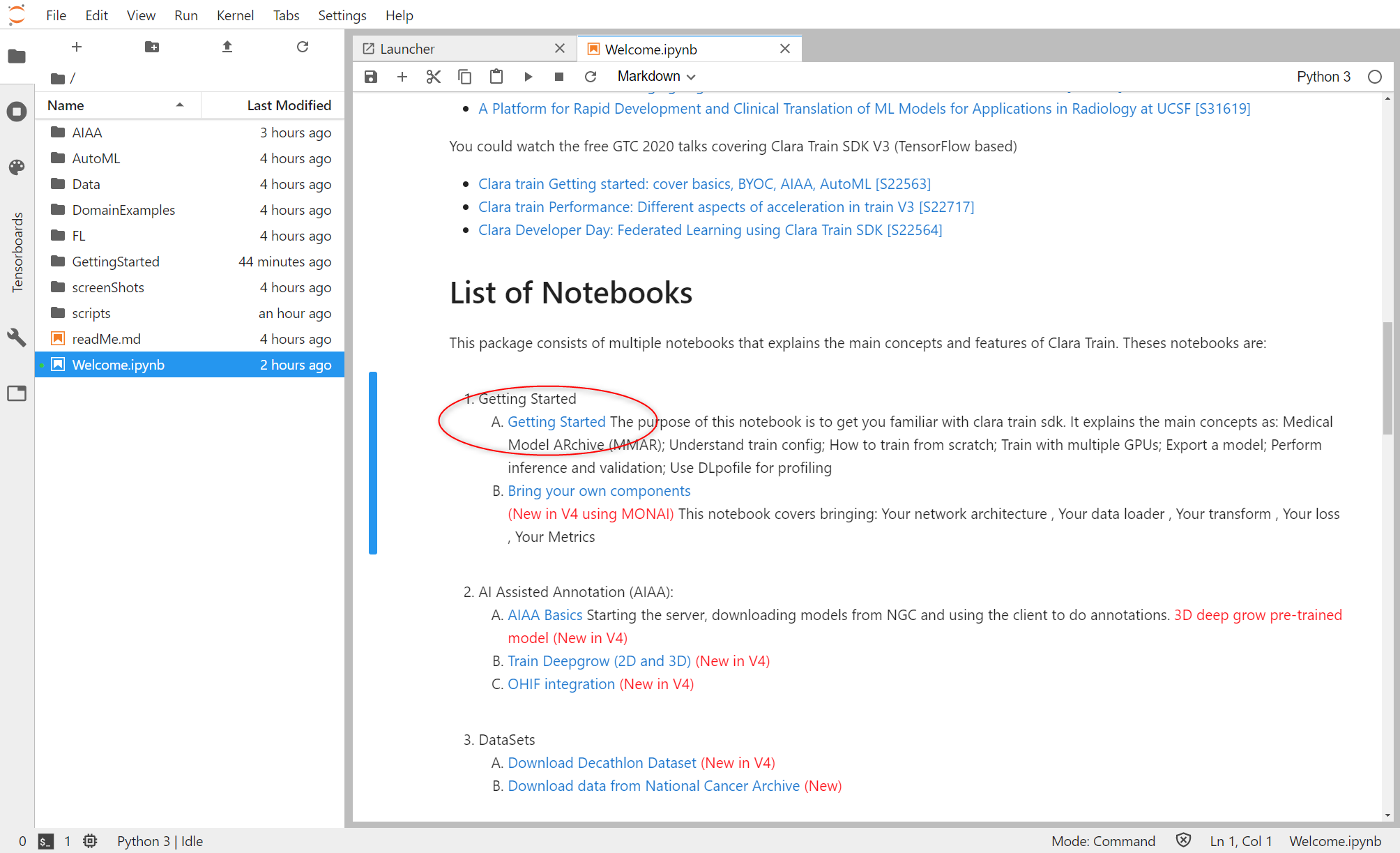
では、お勧めに従って、Gettings Started から始め行きましょうと言いたいのですが、最初の部分は v3.1 と変わりがありません。最初の説明は Medical Model ARichve(MMAR)がどのようなディレクトリ構造になっているなどの解説で、Training の基礎設定値が各ファイルに記載されていることを紹介しています。
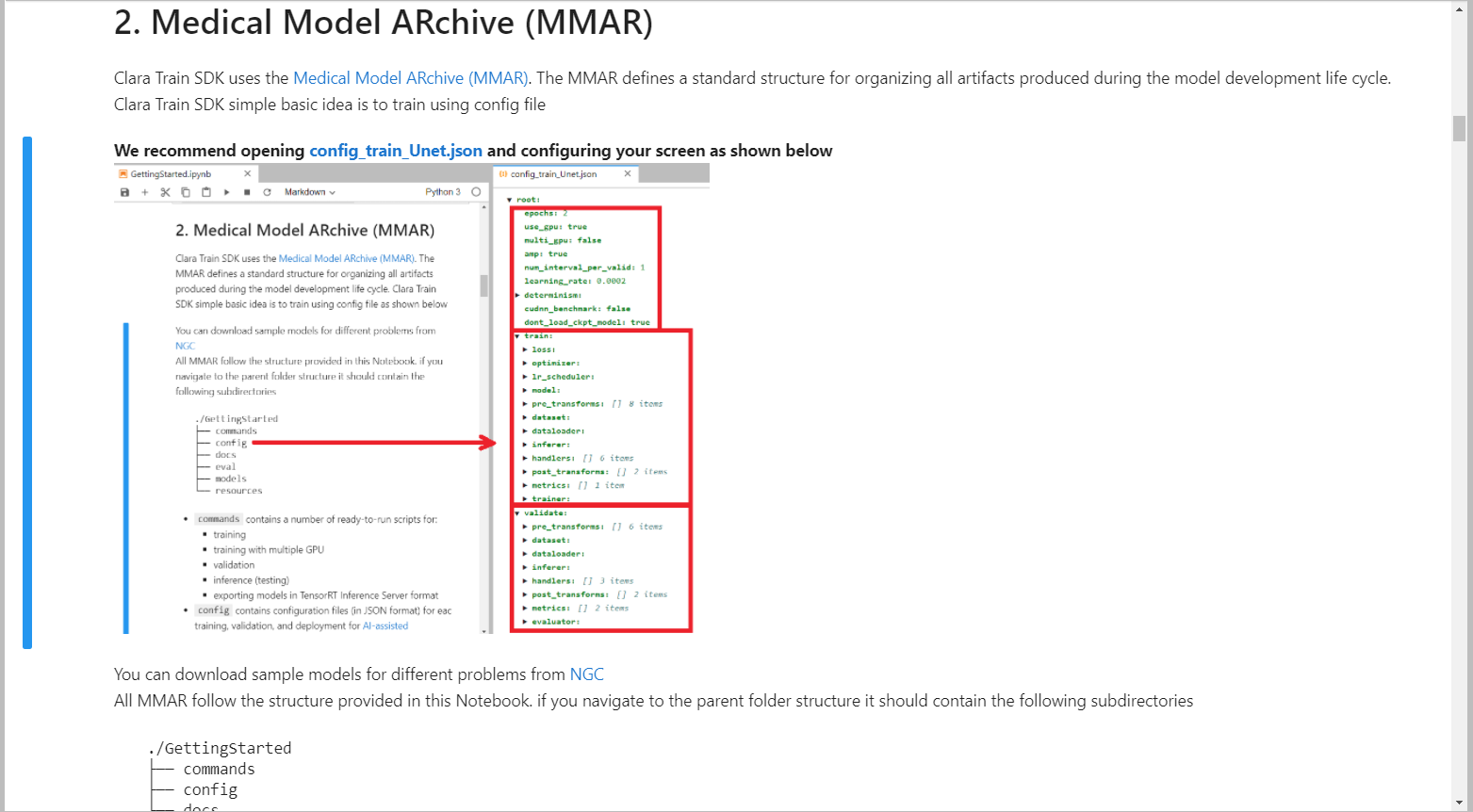
Training の条件が書かれていますので、各項目の内容については、Clara Train SDK Document (MMAR) の内容と合わせて理解する必要があります。本質的な内容ですが、この部分は項目が多すぎ、実際に Training を進めていく際に見直してゆくパラメータになります。流れだけつかむのであれば、Play ボタンを押していけば、DL の基本セットである、Training, Validation, Inference までの1セットの流れを理解することができます。Clara Train SDK に適合する GPU であれば、10分程度で処理は終わります。それ以上時間がかかるのであれば、試用している機体が Training に向いているかどうかよく考える必要があります。Getting Started といいますが、最初ここをすべて理解したうえで次のAIAAに行くのか、それとも、AIAA をある程度進めていくうえで、期待通りの結果にならないので再度ここに立ち戻り調整をするのかと言われれば、AIAAを実際やってみたうえで、ここに戻ってくるのではないかと思います。Finetune にしても Profiling (外部ツール)にしても、一度AIAAを使ってみて、Training 性能の向上などを検討するうえで使用していくツールになってきます。